LLMs_interview_faq
Table of Contents
#
01:简述GPT和BERT的区别
GPT (Decoder-only) 和 BERT (Encoder-only) 都是基于 Transformer 架构的自然语言处理模型,它们在设计上有一些显著区别:
- 任务类型
- GPT 以生成文本为主要任务,其目标是生成与输入文本连贯和相关的文本。因此,GPT 通 常用于生成文本 (如:摘要总结,文本补充和chatbot)。
- BERT 以理解文本为主要任务,其目标是从输入文本中提取语义信息。因此适用于各种文 本理解任务,如:情感分析、 文本分类、命名实体识别等下游任务。
- 预训练目标
- GPT:单向语言建模。GPT通过自左向右的注意力机制来预测下一个单词,即根据上下文预 测下一个单词/词元是什么。
- BERT:双向语言建模。BERT使用掩码语言建模(MLM)和下一句预测(NSP)两个任务,前 者在MLM任务中随机遮掩输入中的一些词语,模型需要预测这些被掩盖的词语是什么; NSP的任务是判断两个句子是否在原文中是前后连接的。
- 结构特点
- GPT:Transformer-decoder的堆叠,仅使用自注意力机制
- BERT:Transformer-encoder的堆叠,包含多层双向Transformer-encoder。在预训练阶段, BERT同时使用了自注意力机制和前馈神经网络。
- 模型微调
- GPT:由于其生成式的特点,GPT在微调时通常将整个模型作为单独的序列生成任务进行微 调。
- BERT:由于其双向表示的特点,BERT在微调时通常用于各种文本理解任务,微调时可以在 模型顶层添加适当的输出层来适应下游特定任务。
#
02:LLM中的因果语言建模与掩码语言建模有什么区别?
因果语言建模(Causal Language Modeling)
在因果语言建模中,模型被要求根据输入序列的左侧内容来预测右侧的下一个词或标记。也就是
说,模型只能看到输入序列中已经生成的部分,而不能看到后续的内容。这种训练方式有助于模
型学习生成连贯和合理的文本,因为模型需要在生成每个词语时考虑上下文的信息,同时不能依
赖于未来的信息。GPT(Generative Pre-trained Transformer)就是以因果语言建模为基础的
模型。
掩码语言建模(Masked Language Modeling):
在掩码语言建模中,模型被要求预测输入序列中一些被随机掩盖或掩码的词语。模型需要基于上
下文来预测这些被掩盖的词语是什么。
这种训练方式通常用于双向的语言理解任务,因为模型需要考虑上下文中的所有信息来预测被掩盖的词语。
BERT(Bidirectional Encoder Representations from Transformers)就是以掩码语言建模为基础的模型。
#
03:请简述Transformer基本原理
Transformer 是一种用于处理序列数据的深度学习模型,由谷歌团队于2017年提出,其主要原理包括 自注意力机制和位置编码。
##
自注意力机制:
允许模型在序列的任意两个位置间直接建立依赖关系,而不考虑它们之间的距离。具体就是将词
元线性转换为三个向量Q,K,V,然后将Q和K用来计算内积(相似度分数)并进行注意力缩放(scaled
dot-product),然后通过softmax归一化,得到每个词元相对于其他词元的注意力权重,然后用
注意力权重对向量V进行加权和计算得到“上下文向量”(context vector),然后将上下文向量用
前馈网络(FFNN)进行变换,就得到编码器隐层输出。注意:自注意力机制中,每个输入词元的
context vector 以及后续的 hidden state,可以看成是相应的 Q 向量的函数,其他的如 K,V,
以及自注意力机制的参数对所有的 Q 都是恒定值。
+ 多头注意力:
在多头注意力中,注意力机制被复制多次,并且每个注意力头都学习到一组不同的Q,K,V的
表示,然后将它们的输出拼接起来,再通过FFNN进行维度对齐。
- 复制注意力机制:原始输入序列会被用来计算多个注意力头(例如8个或16个头)
- 独立学习:每个注意力头都会独立地学习一组Q,K,V的表示,也就是:每个注意力头都
有自己的权重矩阵,将输入序列转换为Q,K,V向量。
- 注意力计算:每个注意力头像单头注意力机制那样计算注意力分数和注意力权重。
- 拼接输出:将所有注意力头的输出拼接成一个向量,形成多头注意力的最终输出。这意味
着每个词元都会得到来自多个不同视角的表示,从而提高模型对输入序列的理解。
- 线性变换:拼接后的输出通过FFNN进行处理,维持输出维度以及融合不同注意力头的信息。
+ narrow attn:Each attention head will get a chunk of the transformed data points
(projections) to work with. This is a details of utmost importance: The
attention heads DO NOT use chunks of the original data points, but rather those
of their projections. It computes the projections first and then chunks them
later, so that each value in the projection is a linear combination of all
features in the data point.
##
位置编码:
位置编码通常是通过将一个与位置相关的向量添加到输入嵌入(input embeddings)
中来实现的。这个向量为序列中的每个位置提供了一个唯一的表示,从而使模型能够
区分不同的单词顺序。
特别是基于 transformer 架构的模型,由于自注意力机制无法捕捉词元顺序,因此必
须通过加入位置编码来获取输入序列中各个词元的位置信息。
尽管自注意力机制(Self-Attention Mechanism)确实可以捕捉序列中元素之间的关
系,但它主要依赖于元素之间的交互和权重计算,而不是它们的绝对位置信息。位置
编码的作用是补充自注意力机制,提供序列中元素顺序的额外信息,使得模型能够更
好地理解序列的结构。
+ 正弦/余弦函数组合编码 (偶数位用 sin(), 奇数位用 cos())
它们为序列中的每个位置提供了一个唯一的、与位置直接相关的编码。这种编码
方式能够明确地告诉模型每个单词在序列中的绝对位置。
绝对位置编码的一个潜在缺点是它们是静态的,不会随着模型训练的进行而改变。
这意味着它们可能不足以捕捉长序列中复杂的依赖关系,特别是在模型需要动态
地调整位置信息以适应输入序列的变化时。
信息的局限性:固定的位置编码仅提供了位置的绝对信息,而没有考虑序列中元
素之间的相对关系。在长序列中,元素之间的相对位置和距离可能更为重要。
+ 旋转位置编码:旋转位置编码的核心思想是将每个位置的编码表示为一个旋转矩阵,
该矩阵可以应用于输入嵌入。旋转矩阵是动态生成的,这意味着它们可以根据输入
序列的内容进行调整,从而更好地捕捉长距离依赖。
##
残差连接与层归一化:
+ 残差连接:将每个子层的输入与其输出相加,然后传递给下一层。这使得模型在学
习过程中,能更容易地学习到残差(输入于输出之差),从而缓解梯度消失问题;
提高训练稳定性;允许更深的网络结构;以及提高模型性能。
+ 层归一化:在每个层的输入之后都应用归一化,即对每个特征维度进行归一化操作,
使得它们均值为0,标准差为1,有助于缓解梯度消失和梯度爆炸的问题,从而使
模型训练更加稳定,也提高其泛化能力。
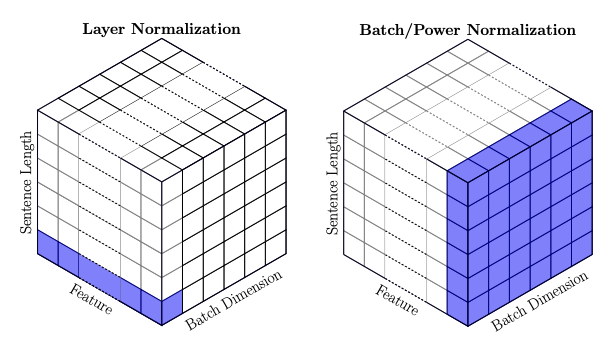
- “批次归一化”(Batch Norm):
The mean and variance statistics used for normalization are calculated
across all elements of all instances in a batch, for each feature
independently.
即:均值和方差是通过对一个批次里所有实例(序列)的所有元素(词元)的某
个特征进行统计的。
- “层归一化”(Layer Norm):
For layernorm, the statistics are calculated across the feature
dimension, for each element and instance independently.
即:均值和方差是通过对某个实例(序列)中的某个元素(词元)的所有特征进
行统计的。
NOTE By "element" and "instance," I mean "word" and "sentence"
respectively for an NLP task, and "pixel" and "image" for a CV task.
#
04: 注意力机制的改良版本们
MHA,GQA,MQA三种注意力机制的区别是什么?
注意力机制在自然语言处理和机器学习领域有多种不同的实现方式,其中常见的包括多头自注意力 (Multi-Head Self-Attention,MHA)、全局注意力(Global Attention,GQA)和多头查询注意力 (Multi-Query Attention,MQA)。这些不同的实现方式在机制和应用上有一些区别:
多头自注意力(MHA):
机制:MHA将输入序列中的每个位置的表示都作为查询(Query)、键(Key)和值(Value),
通过计算查询与所有键的相似度,然后将相似度作为权重对值进行加权求和,从而获得每个
位置的注意力输出。
特点:MHA允许模型在不同的表示空间上进行多头并行计算,通过多头机制,可以学习到不同的关注点和表示。
应用:MHA常用于Transformer等模型中,用于捕捉输入序列中不同位置之间的依赖关系。
全局注意力(GQA):
机制:GQA将所有的输入位置都作为查询,与所有的键计算相似度,然后将所有位置的值根
据相似度进行加权求和,得到一个全局的输出。
特点:GQA考虑了序列中所有位置的关系,但在处理长序列时可能会受到计算资源的限制,
因为需要计算所有位置之间的相似度。
应用:GQA常用于对整个输入序列进行全局的信息聚合,例如在图像分类任务中。
多头查询注意力(MQA):
机制:MQA与MHA类似,但在每个头的注意力计算中,使用不同的查询向量,而不是所有头都共享相同的查询向量。
特点:MQA允许模型为每个头学习不同的查询模式,增强了模型的灵活性和表达能力。
应用:MQA常用于需要根据不同的查询来获取注意力信息的任务,如问答系统或需要针对不同问题进行推理的场景
#
05: Attention的改良版本们
- 简述一下 FlashAttention 的原理
Flash Attention是一种新型的注意力算法,旨在解决传统Transformer模型中自注意力机制的计 算和内存效率问题。由于自注意力机制的时间和存储复杂度与序列长度成二次方关系,这使得处 理长序列数据时面临巨大挑战。Flash Attention通过精心设计,显著减少了对高带宽内存(HBM) 的读写次数,从而加快了运行速度并降低了内存占用。
##
Flash Attention的核心原理和技术:
平铺(Tiling):Flash Attention将输入分割成小块,并在每个块上执行注意力操作。这种方法减少了对高带宽内存的访问次数,因为不需要一次性将整个大矩阵加载到内存中。
重新计算(Recomputation):在后向传播过程中,Flash Attention避免了存储大型中间矩阵(如S和P矩阵),而是利用前向传播中的统计量来快速重新计算这些矩阵,从而减少了内存消耗。
在线Softmax:为了处理Softmax操作,Flash Attention采用了在线Softmax技术,它允许分块计算softmax,并通过适当的归一化因子来确保最终结果的正确性。
内存层次结构意识(IO-Awareness):Flash Attention考虑了GPU内存层次结构,优化了不同层级内存之间的数据访问,如在GPU的SRAM和HBM之间。
##
Flash Attention-2:
在Flash Attention的基础上,研究人员进一步提出了Flash Attention-2,它通过改进工作分配和并行化策略,进一步提高了计算速度。Flash Attention-2的优化包括:
减少非矩阵乘法(non-matmul)的浮点运算次数(FLOPs)。
通过在不同的线程块上并行化注意力计算,提高了GPU的占用率。
在每个线程块内,将工作分配给不同的warp,以减少通过共享内存的通信。
- PagedAttention的原理是什么,解决了LLM中的什么问题?
Paged Attention(PA)技术是一种用于优化大型语言模型(LLM)推理性能的方法,特别是在处理自 回归生成任务时对内存使用效率的显著提升。这项技术的核心思想是借鉴操作系统中虚拟内存和分页 的技术,将传统的注意力机制中的键值对(Key-Value pairs,简称K-V pairs)缓存以分页的形式存 储和管理。
在自回归解码过程中,模型为每个输入令牌生成注意力键和值,这些键值对被存储在GPU的显存中以 预测下一个令牌。由于这些缓存的键值对大小是动态变化的,并且可能会占用大量的显存空间,因此 有效管理这些缓存成为一个挑战。传统的注意力算法在处理时会受限于显存的大小,这限制了模型的 批处理能力和整体的吞吐量。
#
06:LLM微调与量化
30.参数高效的微调(PEFT)有哪些方法? 31.LORA微调相比于微调适配器或前缀微调有什么优势? 32.有了解过什么是稀疏微调吗? 33.训练后量化(PTQ)和量化感知训练(QAT)与什么区别? 34.LLMs中,量化权重和量化激活的区别是什么? 35.AWQ量化的步骤是什么?
#
07:嵌入向量模型
40.自前主流的中文嵌入向量模型有哪些?
#
其他
45.DeepSpeed推理对算子融合做了哪些优化? 48.请介绍一下微软的ZeRO优化器
3.为什么现在的大模型大多是decoder-only的架构? 4.讲一下生成式语言模型的工作机理 5.哪些因素会导致LLM的偏见? 7.如何减轻LLM中的幻觉现象? 8.解释ChatGPT的零样本和少样本学习的概念 10.如何评估大语言模型(LLMs)的性能? 11.如何缓解LLMs重复读问题? 16.Wordpiece与BPE之间的区别是什么? 17.有哪些常见的优化LLMs输出的技术? 18.GPT-3拥有的1750亿参数,是怎么算出来的? 19.温度系数和top-p,top-k参数有什么区别? 21.介绍-下postlayernorm和prelayernorm的区别 22.什么是思维链(CoT)提示? 23.你觉得什么样的任务或领域适合用思维链提示? 24.你了解ReAct吗,它有什么优点? 25.解释一下langchainAgent的概念 26.langchain有哪些替代方案? 27.langchaintoken计数有什么问题?如何解决? 28.LLM预训练阶段有哪几个关键步骤? 29.RLHF模型为什么会表现比SFT更好? 36.介绍一下GPipe推理框架 37.矩阵乘法如何做张量并行? 38.请简述下PPO算法流程,它跟TRPO的区别是什么? 39.什么是检索增强生成(RAG)? 41.为什么LLM的知识更新很困难? 42.RAG和微调的区别是什么? 43.大模型一般评测方法及基准是什么? 50.什么是投机采样技术,请举例说明?