对比学习(Contrast Learning): 是一种自监督学习方法,通过构建和比较正负样本对来学习数据的有用表示。正样本对通常来自同一 数据点的不同增强版本,而负样本对则来自不同的数据点。模型通过最大化正样本对的相似度和最小 化负样本对的相似度,从而提取数据的判别性特征,广泛应用于图像、文本和时间序列等领域。
正负样本的生成:
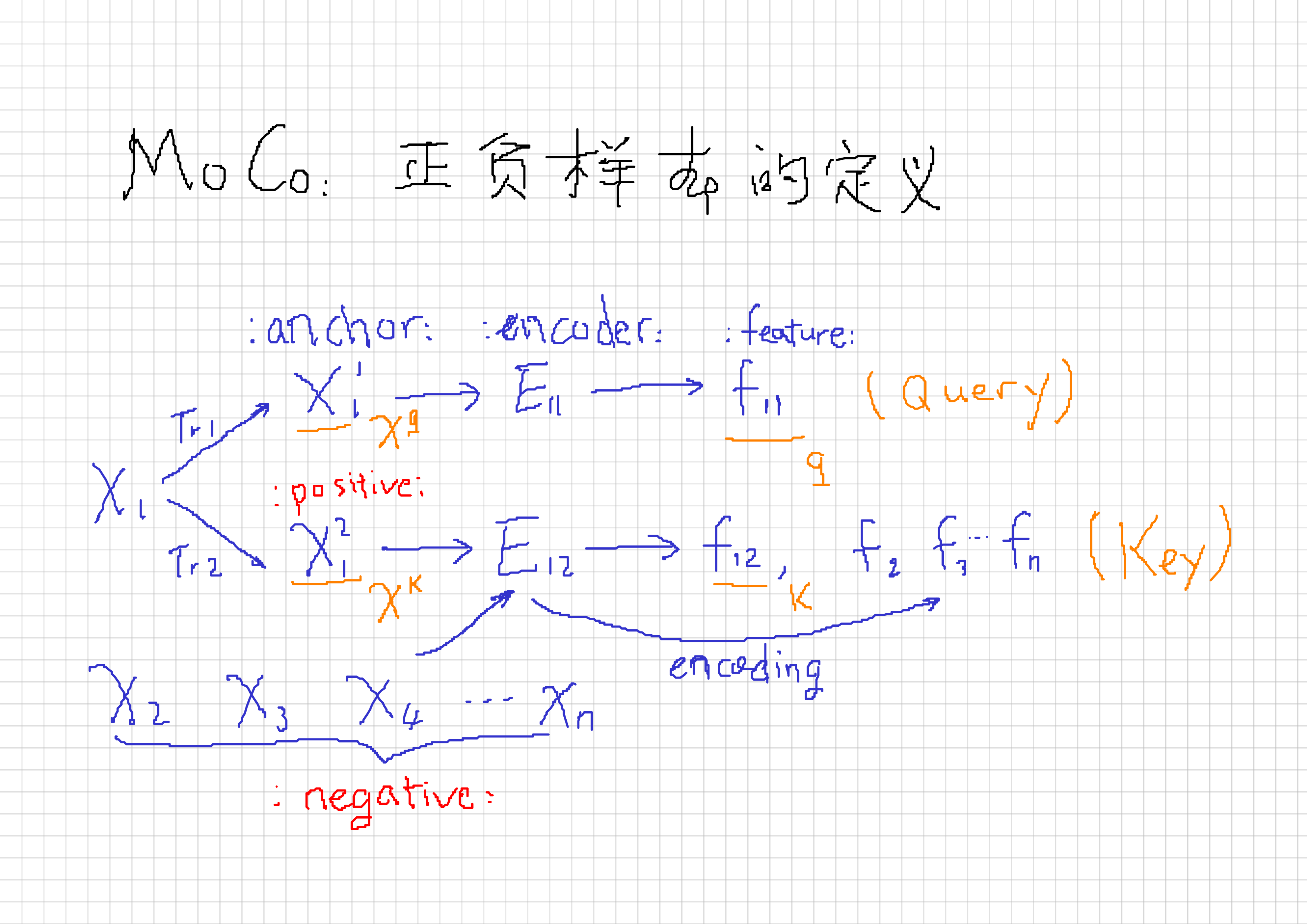
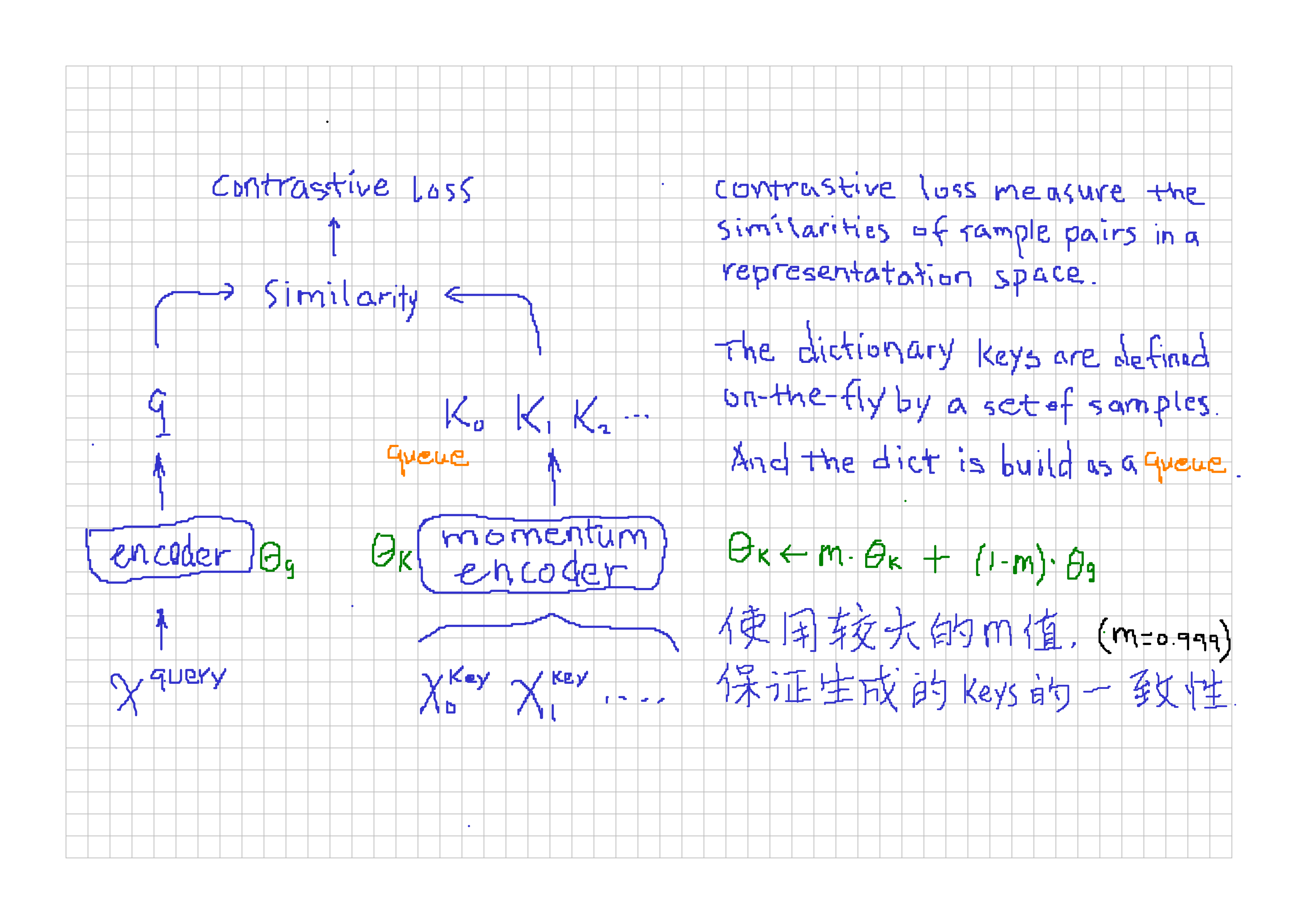
MoCo:
Contrastive learning as dictionary look-up:
queuefor large dictionary of keys: 解决 simCLR(end-to-end) 方法受限于字典大小的问题momentum updatefor consistency of keys: 解决基于 “memory bank” 方法受限于keys的特征一致性差的问题
infoNCE loss (infomation Noice-Contrastive Estimation, 与交叉熵损失有极大关联): NCE是将多分类问题转换为二分类问题(数据样本vs噪声样本)从而可以愉快使用softmax; 而infoNCE认为噪声样本里还是有很多不同类别,所以看成多分类问题比较合理(K+1类)。 交叉熵损失中的$k$是类别数目,而infoNCE损失中的$k$是负样本的数目。
$$ \mathcal{L}_q = - \log \frac{\exp(q \cdot k_{+} / \tau)}{\sum^{K}_{i=0} \exp(q \cdot k_{+} / \tau)} $$