Table of Contents
思维实验: 在浅层网络结构的基础上(比如20层),往后面直接添加更多的同映射隐层(identity layers), 得到的深层网络(比如50层)理论上效果应该不会变差。但实验结果说明,它真会变差。意味着: SGD算法无法找到使得更深层网络性能不变差的参数。
残差网络架构可以解决这个问题。
#
Why, What, and How
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions.
训练一个深度(足够深的)神经网络是一件很难的事情(2015年)。 使用“残差”神经网络架构可以更容易地训练足够深的神经网络。 “残差”架构就是把这些中间层作为一个学习输入与输出的残差的函数。

就是说:增加的隐层去学习 $h(x) - x$(残差)而不是 $h(x)$,而输出的是当前隐层的输出加上前 一层的输出 $x$ (同时也是当前层的输入)。
#
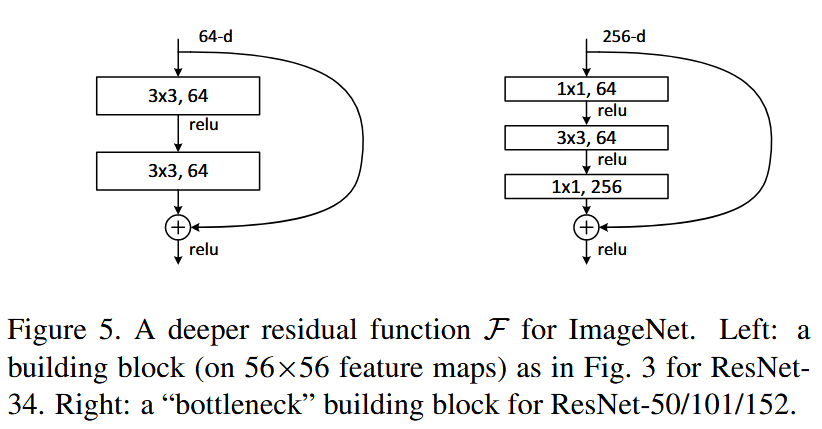
残差网络结构
残差连接(aka, shortcut connection)在输入和输出的维度相同情况下可以直接使用如下结构块:
$$ y = F(x, {W_i}) + x. $$
当想要增加维度时,有两种方式来对齐输入和输出的维度:
残差连接进行同映射操作,然后对增加的维度进行补零操作(padding zeros)
残差连接进行线性投影操作 $y = F(x, {W_i}) + W_s x.$ 来对齐维度(使用 1x1 卷积实现)
两种情况下,当残差连接的是不同尺寸的特征图(feature map)时,使用步幅为2的卷积操作。 (通道数翻倍,则高宽减半,因此使用步幅=2(stride=2)的卷积来保证维数对齐)

#
残差连接为什么有用?
Easier Gradient Flow
- 缓解梯度消失/梯度爆炸问题
- 残差连接使得梯度更稳定
更容易学习同映射函数
提升最优化和收敛效果
更好的特征传播(feature propagation)