BERT模型论文精读笔记
Table of Contents
(李沐-BERT论文精读的个人整理笔记)
BERT论文标题: Pre-training of Deep Bidirectional Transformers for Language Understanding
预训练(pre-training):先在一个大的数据集上训练一个模型(从零开始得到一组权重值W0),这个模
型的主要任务是被用在其他任务(或下游任务上)进行训练(training:以W0初始化模型然后训练)
(以解决下游任务问题)。
BERT本身含义:Bidirectional Encoder Representations from Transformer,使用了 Transformers 模 型(Transformer论文精读)的编码编码器组件,学习一个双向的嵌入表示。与 ELMo 和 Generative Pre-trained Transformer 不同:
- BERT 从无标注的文本中(jointly conditioning 联合左右的上下文信息)预训练词嵌入的双向表征。
- pre-trained BERT 可以通过加一个输出层来 fine-tune,不需要对特定任务的做架构上的修改就 可以在在很多任务(问答、推理)有很不错的、state-of-the-art 的效果
- GPT unidirectional,使用左边的上下文信息预测未来;BERT bidirectional,使用左右侧的上下文信息
- ELMo based on RNNs, down-stream 任务需要调整架构
- GPT, based on Transformers decoder, down-stream 任务只需要改最上层
- BERT based on Transformers encoder, down-stream 任务只需要调整最上层
NLP 任务主要分两类:
- sentence-level tasks 句子级别的任务——情绪识别、语句相似计算、语义检索等;
- token-level tasks 词级别的人物——NER (人名、街道名) 需要 fine-grained output
标准语言模型是 unidirectional 单向的,基于神经网络的 ELMo 和 GPT 也都是单向的,就是从左 到右的架构,只能将输入的一个句子从左看到右,然后是预测下一个单词/词元。然而一些语言理解 任务,比如情感分类、QA,则从左看到右、从右看到左 都应该是合法的。如果能从两个方向看信息, 能提升模型解决这类任务的性能。
BERT 通过 MLM(Masked language model) 带掩码的语言模型 作为预训练的目标,来减轻标准语言模 型的单向约束:
MLM 带掩码的语言模型做什么呢? 每次随机选输入的词源 tokens, 然后 mask 它们,目标函数是预测被 masked 的词;类似挖空 填词、完形填空。
BERT 除了 MLM 还有什么? NSP: next sentence prediction 判断两个句子是随机采样的 or 原文相邻,学习 sentence-level 的信息
总的来说: ELMo 用了 bidirectional 信息,但架构是 RNN 比较老(无法并行计算); GPT 架构 Transformer 新(注意力机制大法好),但只用了 unidirectional 信息; BERT = ELMo 的 bidirectional 信息 + GPT 的新架构 transformer。 毕竟语言任务很多并不是预测未来,而是完形填空。BERT结合这俩,并证明双向有用。
#
BERT 模型
BERT 有两个任务:预训练 + 微调
pre-training: 使用 unlabeled data 训练
fine-tuning: 采用 Bert 模型,但是权重都是预训练期间得到的
- 所有权重在微调的时候都会参与训练,用的是有标记的数据、
- 每一个下游任务都会常见一个 新的 BERT 模型,(由预训练参数初始化),但每一个下游任务会 根据自己任务的 labeled data 来微调自己的 BERT 模型
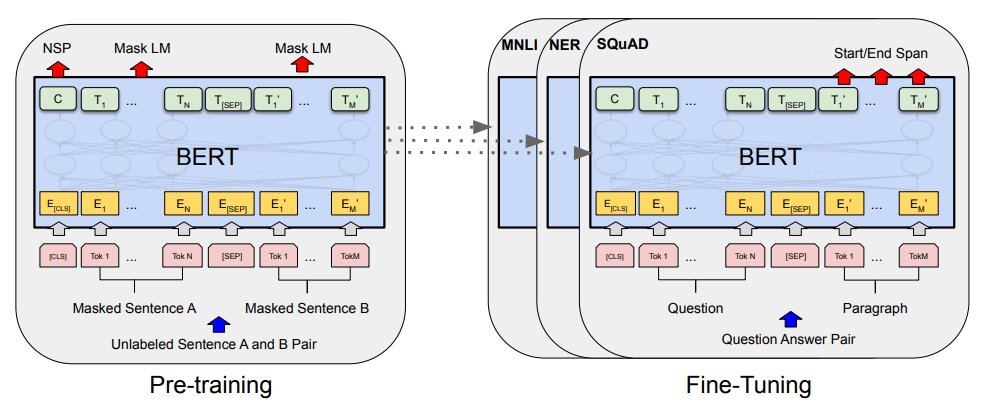
下游任务:创建同样的 BERT 的模型,权重的初始化值来自于 预训练好 的权重。
MNLI, NER, SQuAD 下游任务有 自己的 labeled data, 对 BERT 继续训练,得到各个下游任务自己 的的 BERT 版本
##
模型架构,主要调了三个参数:
- L: transform blocks 的个数
- H: hidden size 隐藏层大小
- A: 自注意力机制 multi-head 中 head 头的个数
主要两个 size:
- 调了 BERT_BASE (学习 1 亿参数,L=12, H=768, A=12)
- BERT_LARGE(3.4 亿参数, L=24, H=1024, A=16)
##
模型输入输出:
- WordPiece 分词(tokenization)
- 输入序列构成:
- [CLS], [SEP]:特殊词元
- 序列开头永远是[CLS],self-attn保证每个token都能联系到其他所有token
- 第一个句子后是[SEP],用于区分两个句子
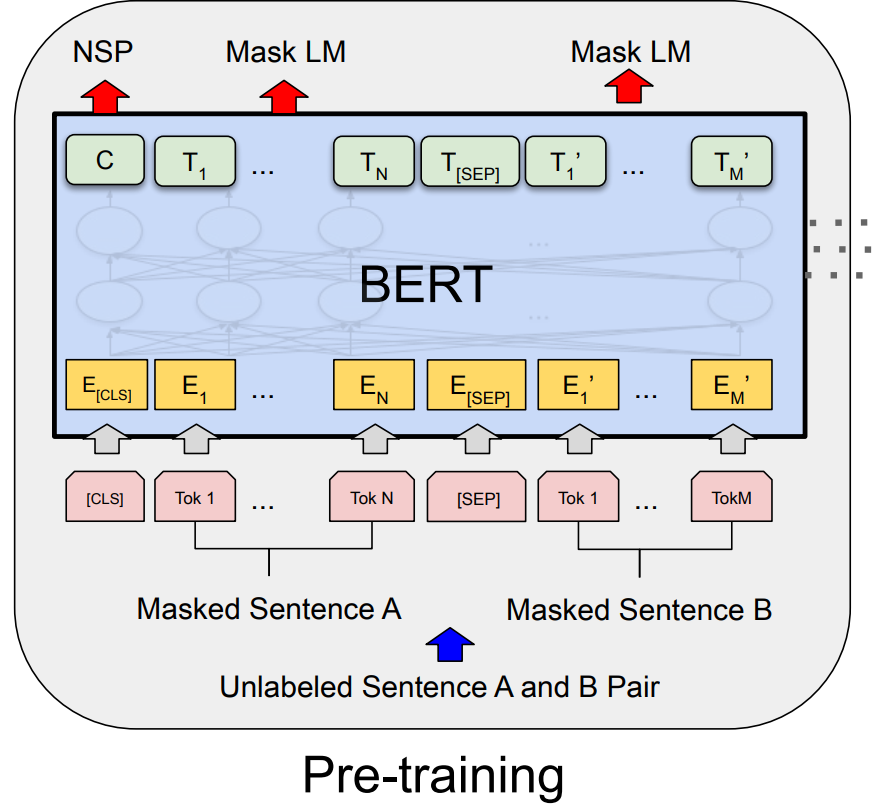
预训练整体过程:
- 每一个 token 进入 BERT 得到 这个 token 的 embedding 表示。
- 整体进 BERT 然后输出一个结果序列
- 最后一个 transformer 块的输出,表示 这个词元 token 的 BERT 的表示。在后面再添加额 外的输出层,来得到特定任务想要的结果
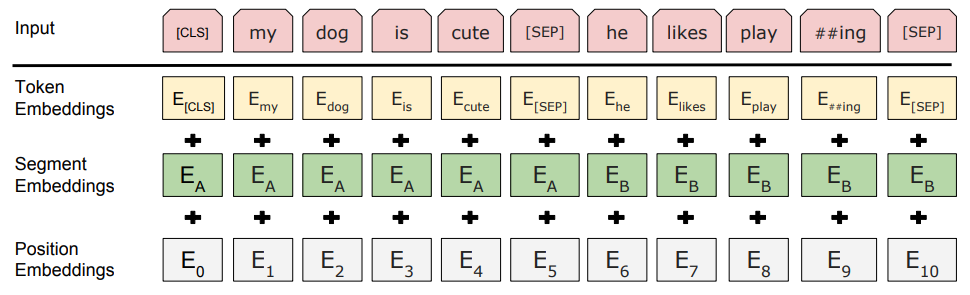
在预训练第一步中得到token的embedding的过程:
- 给定一个词元(token)
- BERT input representation = token 本身的表示 + segment 句子的表示 + position embedding
位置表示
- token embedding:每一个 token 有对应的词向量
- Segment:即到底是 A 句还是 B 句,通过学习得到
- Position:是 token 在这个序列 sequence 中的位置信息。从 0 开始 1 2 3 4 -> N。其最 终值也是通过学习得到的(transformer 是给定的)
- 加起来的话每个向量的信息就会组合在一起
- 从【一个词元的序列】得到【一个向量的序列】,最终可以进入 transformer 块
##
动态掩码策略:
BERT 模型中的 MLM(Masked Language Model) 任务确实引入了一个问题:在预训练阶段,输入序 列中的 15% 的单词被替换为 [MASK],而在微调阶段,模型接收的是完整的自然语言句子,不再有 [MASK] 标记。因此,预训练和微调阶段模型看到的数据分布不一致,这可能会影响微调阶段模型的 表现。
为了解决这个问题,BERT 设计中采取了一些措施:
BERT 的设计者意识到了这个问题,因此在预训练的过程中引入了一种动态掩码策略。虽然 15% 的单 词被标记为需要预测的目标,但并不是所有这些单词都被替换为 [MASK],具体的处理方式是:
80% 的情况下:将目标单词替换为 [MASK]。
10% 的情况下:将目标单词替换为一个随机的其他单词。
10% 的情况下:保持目标单词不变。
这种设计的目的是让模型不仅仅习惯于看到 [MASK] 标记,还可以在预训练时学到更多关于真实单词 的上下文信息。通过这种混合策略,BERT 能够学会在存在 [MASK] 标记时预测缺失单词,同时也能 应对训练过程中未出现 [MASK] 的情况。
#
损失函数
在 BERT 的预训练阶段,主要有两个任务,它们的损失函数与这两个任务紧密相关:
MLM任务中,模型的目标是根据上下文预测被随机掩盖(15%)的单词。这个任务的损失函数是交叉 熵损失函数(cross-entropy loss),它用来衡量模型预测的单词与真实单词之间的差距。
NSP任务中,模型的目标是判断两个句子之间是否具有逻辑上的连续性,即模型要预测第二个句子 是否是第一个句子的下一个句子。NSP 任务同样使用交叉熵损失函数,用于计算模型预测的二分类 结果(连续/不连续)与真实标签之间的误差。
因此,预训练阶段的总损失函数是 MLM 和 NSP 损失函数的加权和,模型通过这个损失函数学习到上 下文的语言信息。
在微调阶段,BERT 不再使用 MLM 或 NSP 任务,而是根据具体的下游任务定义新的损失函数。
文本分类任务(如情感分析): 微调阶段的文本分类任务通常基于 [CLS] token 的输出,使用这个向量来预测类别。此时的损 失函数依然是交叉熵损失函数,用于计算模型预测的类别分布与真实类别之间的差异。
序列标注任务(如命名实体识别 NER): 在序列标注任务中,BERT 的每个 token 会被映射到一个标签,这类任务的损失函数也是交叉熵 损失,但它是针对每个 token 预测结果和实际标签之间的差异计算的。
问答任务(如 SQuAD): 在问答任务中,BERT 会生成两个标量,一个表示答案的起始位置,另一个表示答案的结束位置。 对于这些位置预测,同样使用交叉熵损失函数。
因此,微调阶段的损失函数完全取决于具体任务的性质,通常会选择合适的损失函数来优化任务的最终目标,而不再使用 MLM 和 NSP 的损失。